RabbitMQ message queueing system and web applications
23/01/2016 - RABBITMQ
The whole purpose of adoption queuing system in web applications is to prevent delays that users experience. Delays occur while waiting for the result when sending emails, processing images (resizing, cropping etc), handling CSV files, creating PDF files so on after a short HTTP request made by users. A busy website cannot handle all these processes in real time because it takes time and requires a lot of memory so they have to be queued and done later on one by one with a messaging system like RabbitMQ. In this post, we're going to focus on RabbitMQ. For more information, visit RabbitMQ site and make sure to read AMQP Model.
Consumer notes
- PHP consumers/workers often cause memory leaks and crash. In general, PHP really fails in long running tasks and you have to deal with stability issues. Try not to use PHP consumers/workers for RabbitMQ and try to find much better suited languages to run long running tasks.
- If all your consumers are busy, the queues might get filled up so you might as well run more consumers as an instant solution.
Some useful commands
# Start server
$ rabbitmq-server
# Check status
$ rabbitmqctl status
# List queues
$ rabbitmqctl list_queue
# Check if messages unacknowledged turned on or off
$ rabbitmqctl list_queues name messages_ready messages_unacknowledged
# List all available exchanges
$ rabbitmqctl list_exchanges
# List all bindings
$ rabbitmqctl list_bindings
# Delete all queues in one go
$ rabbitmqctl stop_app
$ rabbitmqctl reset
$ rabbitmqctl start_app
Common questions
- What happens to messages on the queue after PC or RabbitMQ service restart?
- Read up on "message durability".
- If I had more than one consumers consuming messages from a specific queue, would messages evenly distributed to consumers?
- Read up on "round-robin dispatching".
- What happens to my message when the consumer dies while processing?
- Read up on "messages unacknowledged".
- If all the consumers are busy what happens?
- Your queue will fill up so you might need to run more consumers.
- How do I recover/redeliver unacknowledged RabbitMQ messages?
- Unacknowledged messages occur when a message gets delivered to a consumer but never been processed or rejected so in simple terms it gets stuck in a queue. Consumer originally receives a message from a specific channel or connection. If this relation is broken for some reason, RabbitMQ wouldn't be able to work out which channel or connection to use to acknowledge or reject so the message stays unacknowledged. The best solution is to close the associated connection so the message gets delivered to a different consumer via a different channel or connection. Other solution is to restart RabbitMQ server!
What is RabbitMQ?
RabbitMQ is a message broker that receives messages from producers and passes them to consumers. Right in the middle, it can route and store messages based on the given rules by developer.
- Producer - Sends messages to Exchange.
- Exchange - Catches messages from Producer and passes them to Queue. Exchange is an optional.
- Binding - Set of rules that are defined on Exchange to decide which message should be passed to which Queue.
- Queue - Stores messages passed by Exchange.
- Consumer - Processes messages that came from Queue. Consumers always know which Queue to listen.
Example case: Assume that there are 5 Producers, 5 Queues and 5 Consumers in our system. We want to resize an image. P1 sends the message to E. E passes the message to Q1. C1 catches message and resizes it. Why always C1? It is because Exchange has a binding rule set by you, that's why! If the rules were set differently, all the other consumers could get messages as well.

The main idea of the messaging model in RabbitMQ is that the producer shouldn't send messages directly to a queue. Instead, it should send messages to an exchange and then they get delivered to specific queues based on user defined rules.
Notes
- For the memory management, pay attention to "statistics database
rabbit.collect_statistics_intervaland "retention policies" features. This is important! - Only the Exchange and Queue are part of RabbitMQ server. Producer and Consumer are your own applications.
- Producer gets triggered only when it is needed.
- Consumer always runs in the background.
- Queues have no limits so they can store unlimited amount of messages.
- Messages are load balanced between consumers by default. This is called "Round-robin dispatching" in RabbitMQ.
- There aren't any message delivery timeouts.
- Message acknowledgments are turned off by default.
- Queues and messages are not often marked as "durable" by default so you must explicitly do it yourself.
- Fair dispatch is disabled by default so you must explicitly do it yourself.
- The use of exchange is optional but recommended as it represents the "best practice".
- Binding keys cannot be declared on "fanout" exchange types.
- Fanout exchange delivers messages to queues randomly without applying any rules so you won't get any change to select which message should go to which queue.
- Direct exchange will give you change to select which message will go to which queue.
- If neither of
routing_keyandbinding_keyare set, direct exchange will behave like fanout and send the messages to all the queues it knows. - Routing keys are defined on messages.
- Binding keys are defined on queues.
- Any message that doesn't match binding rules will be discarded and won't be delivered to any queues.
- If the binding key consists of just a
#sign without words in the case of topic exchange, topic exchange will behave like a fanout exchange and deliver messages randomly. - If no signs are used as part of binding keys in the case of topic exchange, topic exchange will behave like a direct exchange so it will deliver messages to matching queues.
- RPC is used when client wants to receive response after whole process.
- Always make sure that all the necessary components are available in RabbitMQ server such as exchange, queue etc. and bound together otherwise if the application is run before consumer, messages will be lost.
- Pay attention to Heartbeats feature. If your application gives you an option to set it, consider setting it.
Work Queues
Queues are used to prevent running resource-heavy tasks as soon as a HTTP request comes in and wait for the response. Instead of this basic logic, we do things later so the request is turned into a message and passed on to a queue to be stored. After that the consumer consumes messages in the queues to finish off the work. As simple as that!
Round-robin Dispatching
In short terms, it means parallelising the work in between consumers. If you run many consumers for a specific work in the background, on average every consumer will get the same number of messages. This is a default behaviour of RabbitMQ.
Example scenario: There are 5 messages and 2 consumers. Consumer 1 will get message 1, 3 and 5 on the other hand consumer 2 will get message 2 and 4. If message 6 comes in, it will be delivered to consumer 2 to make things even.
Message Acknowledgement
For any random reason, a consumer could die in the middle of a process and we would lose all the messages delivered to this particular consumer which is a very scary scenario. In such case, what we would want is to deliver unfinished and all the messages to any other available consumer instead.
RabbitMQ uses "message acknowledgments" logic to prevent message loss. Consumers send a message acknowledgments back to RabbitMQ telling that the particular message has been received and processed successfully then RabbitMQ deletes it. If our "scary" scenario occurs, consumer won't be able to send a message acknowledgments back to RabbitMQ because it is dead. In such case, RabbitMQ will know that something went wrong and will re-queue it which will then be picked up by any other available consumers. This ensures us that messages won't get lost.
Message acknowledgments are turned off by default so you must explicitly turn them on to send a message acknowledgment from the consumer after finishing the work.
Message Durability
For any random reason, if the RabbitMQ server stops working it would forget the queues and the messages which is something you don't want to see happening however fortunately you could prevent it by marking queues and messages "durable". Queues and the messages are not often marked as "durable" by default so you must explicitly do it yourself.
Initially, you need to declare your queue "durable" but beware that if the queue already exists you cannot change its settings so you need to declare a new durable queue. It has to be done in both the producer and consumer code. Next, you need to declare your message "persistent" by setting the delivery_mode = 2 as message property.
Note on message persistence: It tells RabbitMQ to save the message on the disk however there are some very rare cases where the message is accepted by RabbitMQ but not saved on the disk yet so this scenario doesn't fully guarantee that a message won't be lost. If you want a 100% guaranteed option, use publisher confirms (Publisher Acknowledgements).
Fair Dispatch
We know that the round-robin dispatching feature dispatches messages to consumers evenly so each consumers get average same amount of messages to process. Lets think about this scenario - there are 5 messages and 2 consumers. Consumer 1 will get message 1, 3 and 5 on the other hand consumer 2 will get message 2 and 4. Lucky enough messages 1, 3 and 5 require very light work to be done whereas messages 2 and 4 require very heavy work to be done so you should feel sorry for consumer 2.
To prevent this behaviour, we need to tell RabbitMQ not to give more than one message to a consumer at a time so what that means is, don't dispatch a new message to a consumer until it has processed and acknowledged the previous one. It is done by using basic_qos() method with prefetch_count = 1 setting.
Publishers/Subscribers
In the case of work queues, each messages are delivered to a single consumer. Delivering a message to multiple consumers is known as "publish/subscribe".
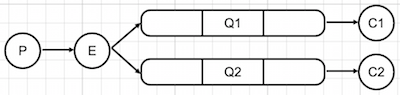
Exchange
Exchange sits in between producers and queues so it receives messages from producers and pushes them to specific queues based on user defined rules. The rules are defined by the exchange type. Messages are either pushed to a single queue or many queues or discarded. In short terms, exchange will do what you tell it to do with the messages.
There are four exchange types which are direct, topic, headers and fanout.
Fanout Exchange
It delivers all messages to all queues it knows so there is no filtering or differentiation is going on here. It just delivers messages randomly and you have no control over in which queue messages will go. Messages are pushed to the queue with the name specified by routing_key only If it is defined by user, however it doesn't apply to fanout exchange.
Bindings
Binding is a relationship in between exchange and queue. Exchange follows the binding rule to pass given message to correct queue. This method normally accepts binding_key but it doesn't apply to fanout exchange type.
Routing
Routing uses binding keys to filter and pass specific messages to correct queues from exchanges but it doesn't apply to fanout type. The binding key is the third argument in queue_bind method.
Direct Exchange
Messages are sent to the queues whose "binding key" matches the "routing key" of the message. It gives you change to select which message will go to which queue. If neither of routing_key and binding_key are set, direct exchange will behave like fanout and send the messages to all the queues it knows.
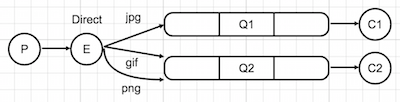
Example above has direct exchange which has two queues bound to it. The Q1 is bound with jpg binding key and the Q2 is bound with gif and png binding keys. The messages with jpg routing keys go to Q1 and are consumed by C1. The messages with gif and png routing keys go to Q2 and are consumed by C2.
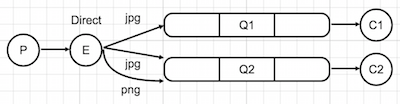
Multiple Bindings
We can use same binding key to pass messages from one exchange to multiple queues. As you can see below, messages with jpg routing keys go to Q1 and Q2.
Topic Exchange
It is similar to direct exchange so a messages are sent to the queues whose "binding key" matches the "routing key" of the message. The difference in between these exchanges is, the binding keys in topic exchange must be a list of words which are delimited by dots and they can contain * and # signs. Star means exactly one word. Hash means zero or more words. The limit of the binding key has a limit of 255 bytes. Example: create.pdf, delete.csv, uefa.europa.league, *.europa.*, champion.# so on.
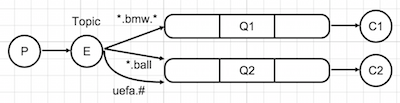
Based on the binding keys shown above, this is what happens:
- Q1 gets all the messages that have exactly three words but the one in the middle must be bmw. Example:
new.bmw.expensive,yes.bmw.yesso on. - Q2 gets all the messages that have exactly two words but must finish with ball and also gets all the messages that start with uefa with no limits. Example:
black.ball,white.ball,uefa,uefa.football,uefa.champions.leagueso on. - Any message that doesn't match these rules will be discarded.
If the binding key consists of just a # sign without words, topic exchange will behave like a fanout exchange and deliver messages randomly. If no signs used in binding keys, topic exchange will behave like a direct exchange so it will deliver messages to matching queues.
RPC
Remote procedure call (RPC) is used when you need a response after whole messaging process. To be able to receive a response from the server, the client must send a "callback queue" address as part of request. We would need to use reply_to (used to name a callback queue) and correlation_id (used to correlate RPC responses with requests) message properties in RPC calls.
The correlation_id property must be unique for each requests. When we receive a message in the "callback queue" we'll check correlation_id property to match the response with our request. In some cases, you might get duplicated responses so it is up to you to handle them appropriately.
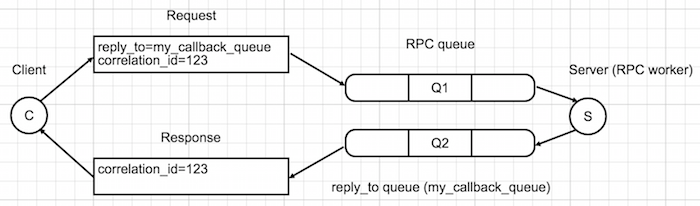
This is how RPC call works:
- When the client starts, it creates an anonymous callback queue.
- Client sends the message with
reply_to(name of callback queue) andcorrelation_id(unique value of requests). - The request is sent to RPC queue.
- RPC worker catches the request, finishes the job and sends the response to correct queue which was defined in
reply_toproperty. - Client catches the response and checks the
correlation_id. If it is a match then deals with it, if not then discards it.